Datenbanken für Fortgeschrittene
Datenbankschema
Das Beispielprogramm
Das Szenario für dieses Beispiel soll folgendermaßen aussehen: Eine große Spedition hat mehrere Lagerhallen an unterschiedlichen Standorten. In allen Lagerhallen werden Waren in unterschiedlicher Stückzahl gelagert, wobei ein Artikel auch in mehreren Lagerhallen vorhanden sein kann. Die Verwaltung der Spedition benötigt nun eine Lagerhaltungssoftware, damit sie immer den Überblick hat, welcher Artikel an welchen Standorten in welcher Anzahl vorhanden ist.
Zu diesem Beispiel entwickeln wir nun ein Datenbankschema. Dies ist immer der erste Schritt, noch bevor man anfängt zu programmieren. Dazu genügt (in einfachen Fällen wie diesem) ein Blatt Papier und ein Bleistift. Für komplexere Fälle gibt es spezielle Software, mit der man solche sog. Entity Relationship-Diagramme entwerfen kann.
An dieser Stelle können natürlich nicht alle Datenbank-Grundlagen abgehandelt werden; wir gehen nur so weit, wie es für unser Beispiel nötig ist. Wer sich tiefergehend mit Datenbanken befassen will, sollte sich auf jeden Fall die Fachliteratur ansehen.
Zum Entwerfen eines Datenbankschemas benötigt man eine ähnliche „Idee“, wie beim Entwickeln von Klassen oder überhaupt zum Programmieren allgemein. Diese „Erfahrung“, welche Daten man in welche Tabellen steckt, erlangt man hauptsächlich durch Übung. Oft sind auch mehrere „Lösungen“ durchführbar. Wie auch beim Programmieren gibt es für alles mehrere Möglichkeiten.
Redundanz und Inkonsistenz
Doch zurück zu unserem Beispiel. Ein wichtiger Grundsatz beim Entwerfen eines Datenbankschemas ist, keine Daten mehrfach zu speichern (sog. Redundanz). Es wäre also schlecht, wenn wir nur eine Tabelle nach folgendem Schema entwerfen:
| ID | Artikel | Anzahl | Lager_Ort | Lager_Tel |
| 1 | Turnschuhe | 25 | Stuttgart | 0711/5678 |
| 2 | Radiergummis | 1028 | Stuttgart | 0711/5678 |
An nur zwei Beispieldatensätzen offenbart sich bereits das Problem: Wenn das Lager in Stuttgart eine neue Telefonnummer bekommt, müssen alle Datensätze korrigiert werden. Wird nur einer übersehen, sind die Daten inkonsistent. Man erhält also für ein Lager mehrere Telefonnummern. In diesem Fall kann man die richtige vielleicht durch Ausprobieren herausfinden. Würde es sich jedoch um Artikelnummern handeln, wäre das nicht so einfach.
Aus diesem Grund legen wir eine extra Tabelle mit den Lagerdaten an. Außerdem benötigen wir eine Tabelle, in der alle Artikeldaten gespeichert sind. Und zu guter Letzt eine Tabelle, in der die Anzahl eines bestimmten Artikels in einem bestimmten Lager abgelegt wird. Die ersten beiden Tabellen enthalten also die Grunddaten, die sich selten ändern. Was sich häufig ändern wird, sind die Daten in der dritten Tabelle.
Verbindungen zwischen Tabellen: Primär- und Fremdschlüssel
Die Frage ist jetzt noch, wie man in der dritten Tabelle angibt, auf welchen Artikel und auf welches Lager sich ein Datensatz bezieht. Dafür haben sich kluge Köpfe folgendes System ausgedacht: Grundsätzlich wird jeder Datensatz in jeder Tabelle mit einer eindeutigen Nummer versehen, dem sog. Primärschlüssel. Über ihn lässt sich ein Datensatz eindeutig identifizieren. Nun besteht die Möglichkeit, in der dritten Tabelle eine Datenspalte einzufügen, in der eine Zahl gespeichert wird, nämlich genau der Primärschlüssel des Datensatzes einer anderen Tabelle. Eine solche Zahl, die auf eine andere, eine fremde Tabelle verweist, nennt man Fremdschlüssel.
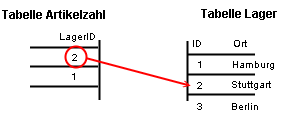
Letztendlich sieht unser Datenbankschema dann so aus:

Die Umsetzung mit Hilfe der Datenbankoberfläche wird hier nicht beschrieben. Dies war Teil des Tutorials Datenbanken-Einstieg.